
On the 23rd of July, Meta revealed the introduction of the Llama 3.1 lineup of multilingual, large language models (LLMs). This collection includes both models that are pre-trained and those that have been fine-tuned for text in/text out tasks, featuring open-source generative AI models in capacities of 8B, 70B, and—for the initial time—405B parameters.
Llama 3.1 405B is the first model that can match the best AI models in many areas like general knowledge, control, math, using tools, and translating languages. With the 405B model, we’re ready to boost innovation, opening up new chances for growth and discovery. We think the new Llama will spark new uses and ways of modeling, like creating synthetic data to help train smaller models, and model distillation, which has never been done on this level before in open source.
Model evaluations
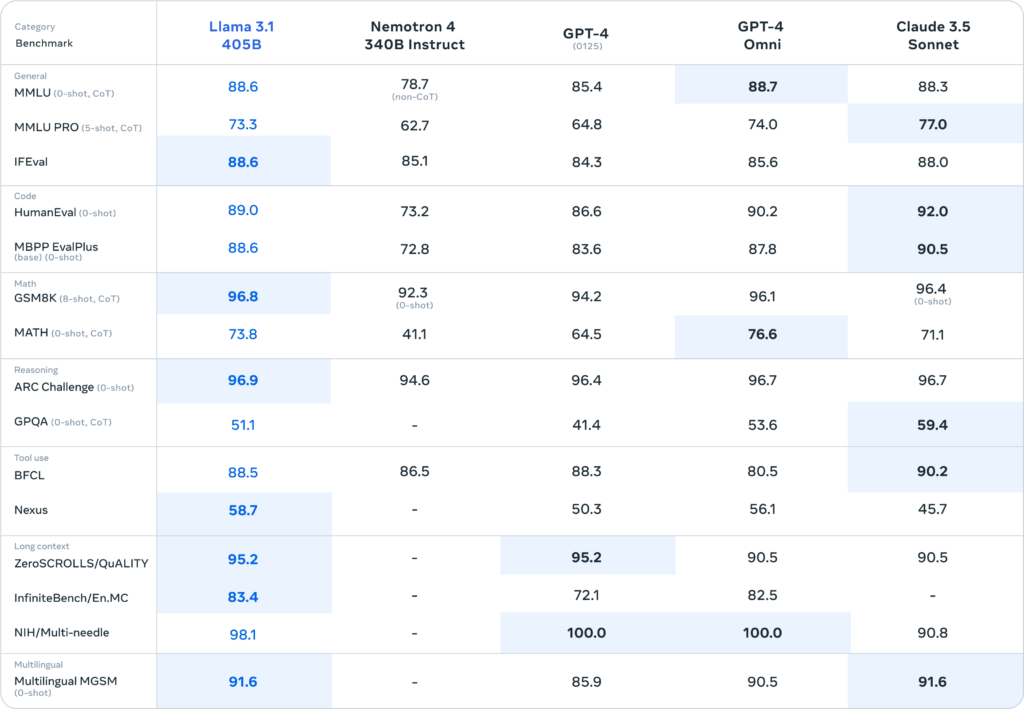
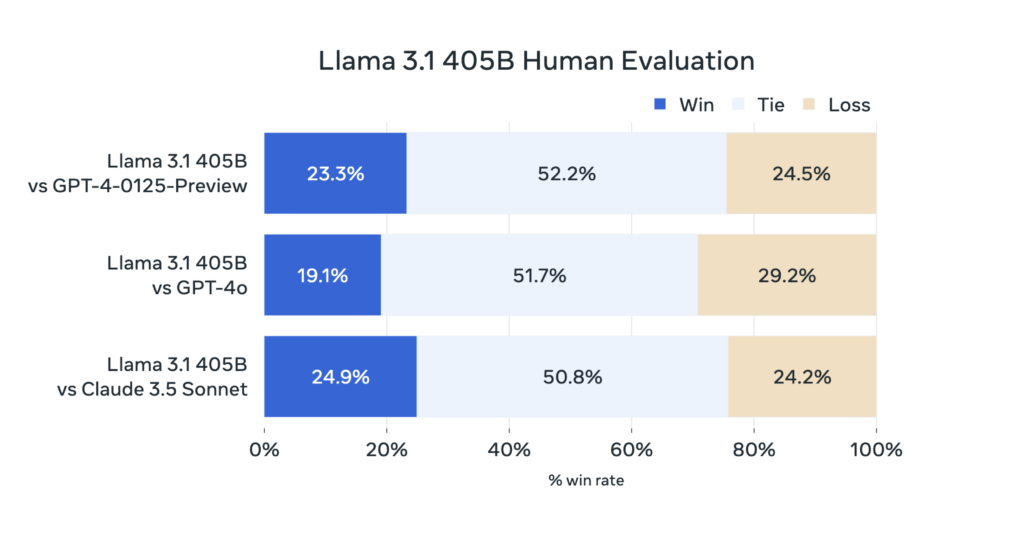
In this update, we tested Llama 3.1 against more than 150 benchmark datasets in various languages. We also did detailed tests with humans to see how it compares to other models in real situations. Our main model did well against top models like GPT-4 and GPT-4o, and Claude 3.5 Sonnet. Our smaller models also did well against models with similar numbers of parameters, both closed and open.
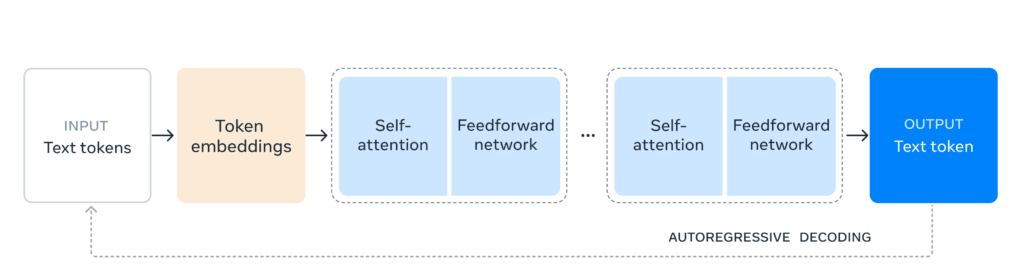
Model Architecture
Training Llama 3.1, our biggest model to date, with over 15 trillion tokens, was a big challenge. To make training runs large enough and fast, we made big improvements to our training setup and used over 16,000 H100 GPUs, setting a new record for the largest Llama model trained.
Meta’s latest version of Llama 3.1 is a big deal in the AI world. It’s just as good as top-secret AI models and aims to make AI more accessible, encouraging new ideas and setting high standards for working together and being open.
Although OpenAI’s GPT-5, expected to be really smart, might compete with Llama 3.1, Llama 3.1’s good results against GPT-4o show the strength of open-source AI. This ongoing development could make AI technology more available and speed up new ideas in tech.

